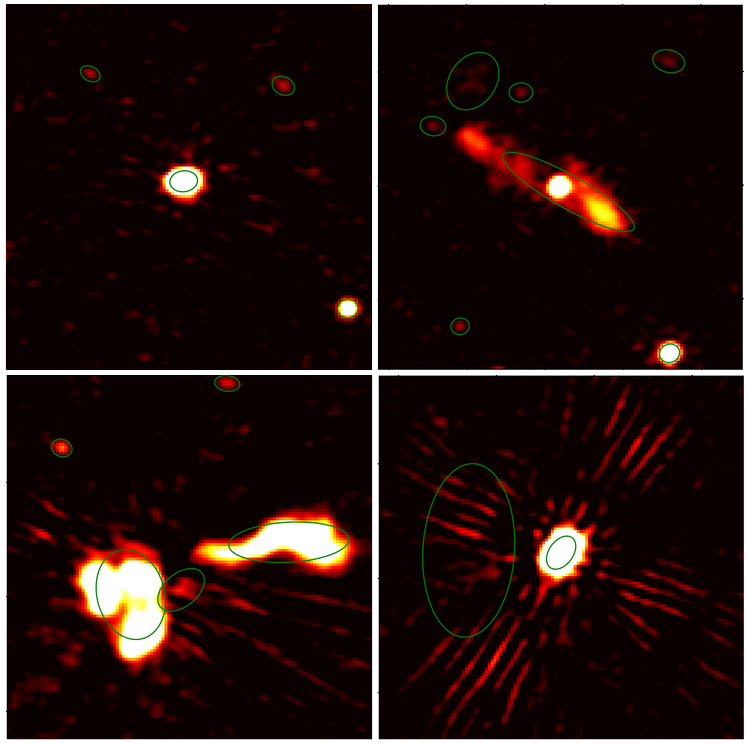
3.2' sided close-up on classical detections in LOFAR 144 MHz continuum data. The detections from Shimwell+ 2022 [2] are the green ellipses. The figure shows in the top left frame the simple case with few point sources and no strong artifacts; in the top right frame an ANG with jets; in the bottom left a blended emission; and in the bottom right frame small sources with bright artifacts around. The pixel values are normalized surface brightness with an arbitrary unit.
Today's radio interferometers produce complex and large data, reaching the PB scale. Classical methods commonly used for source detection and characterization struggle with such data due to specific morphologies or artifacts, leading to false detections, and have poor scaling with data size and dimensionality.
Classical methods will be even more challenged by the forthcoming Square Kilometre Array (SKA), which is expected to generate 700 PB of archived data per year and a raw output of about 1 TB per second.
To develop new analysis methods, the community can rely on data from SKA precursors (MeerKAT, ASKAP, MWA, HERA) and pathfinders (LOFAR, NenuFAR, VLA, ...), as well as the Science Data Challenges (SDCs) from the SKA Observatory (SKAO). This provides a robust framework to prepare for SKA data analysis.
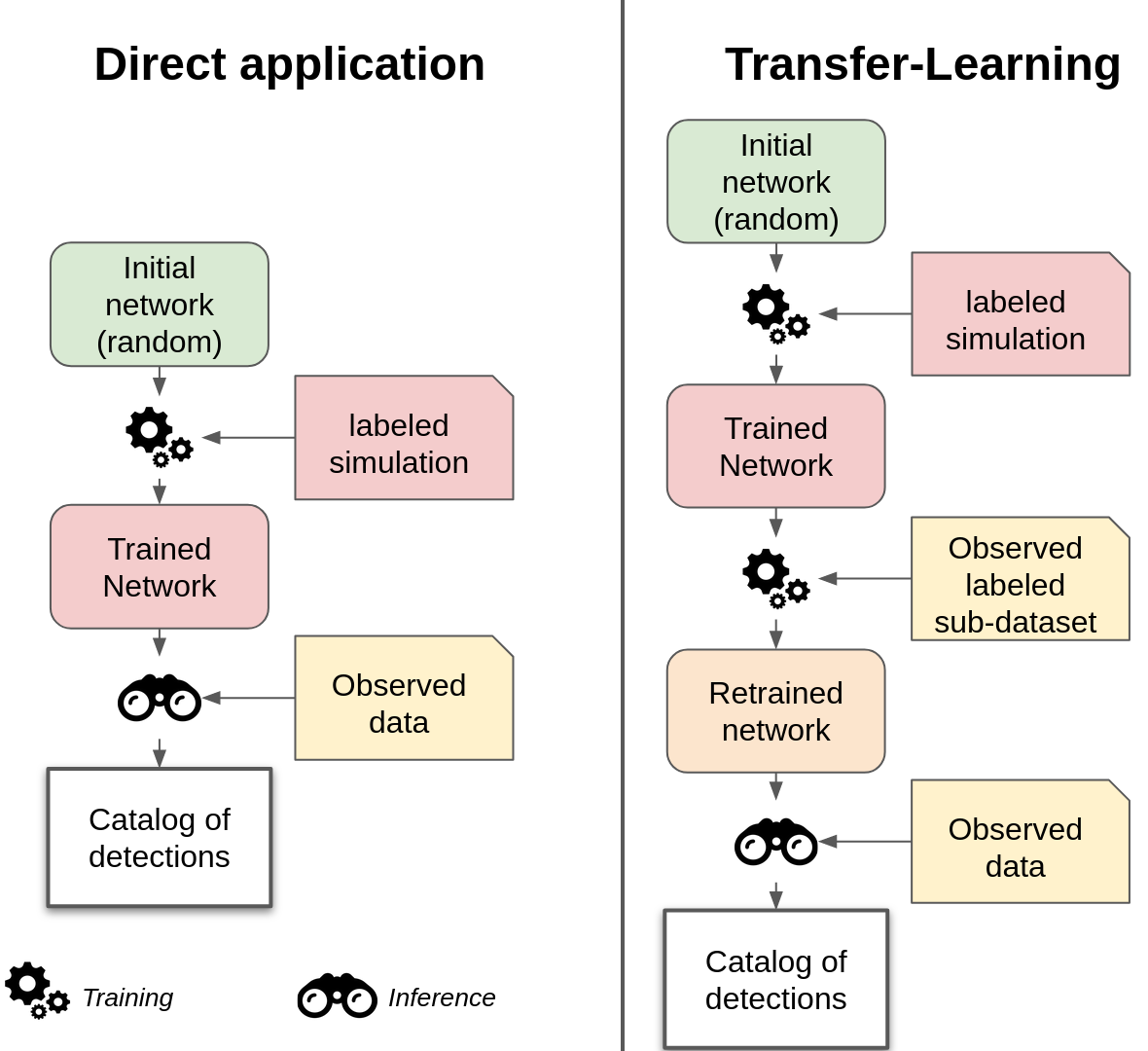
The MINERVA team (MachINe lEarning for Radioastronomy at the Observatoire de Paris) developed a supervised deep learning method, YOLO-CIANNA, in the context of the SKAO SDCs. With this method, the team reached the first place in SDC2 and the highest score a posteriori on SDC1 data (Cornu+ 2024 [1]). This method shows state-of-the-art performance on simulated data, and we aim to apply it to observational data from SKA precursors and pathfinders.