Although rare, massive stars (M∗ > 8−10 Msolar ) play a crucial role in the Universe, as they
- display strong stellar winds
- deposit energy and momentum to the interstellar medium
- produce a series of elements
- shed chemically processed material as they evolve
- enhance the galactic environment of their host galaxies when exploding as supernovae
- die as neutron stars or black holes, offering insights to extreme physics (gravity, temperature)
- are progenitors of gamma-ray bursts and gravitational wave sources
- are very luminous and can be observed in more distant galaxies > ideal tool to understand stellar evolution across cosmological time, especially for first galaxies (such as those to be observed with James Webb Space Telescope).
However, we still lack knowledge, especially for the evolution of massive stars beyond the main-sequence.
Key factors that determine their evolution:
- initial mass
- metallicity
- stellar rotation
- mass-loss
- binary interactions.
In particular, mass loss
- affects strongly the stellar evolution
- enriches the immediate circumstellar environment
- forms complex structures (shells, disks, etc.).
Mass loss is not homogeneous, even at the simplest cases of stellar winds from single stars.
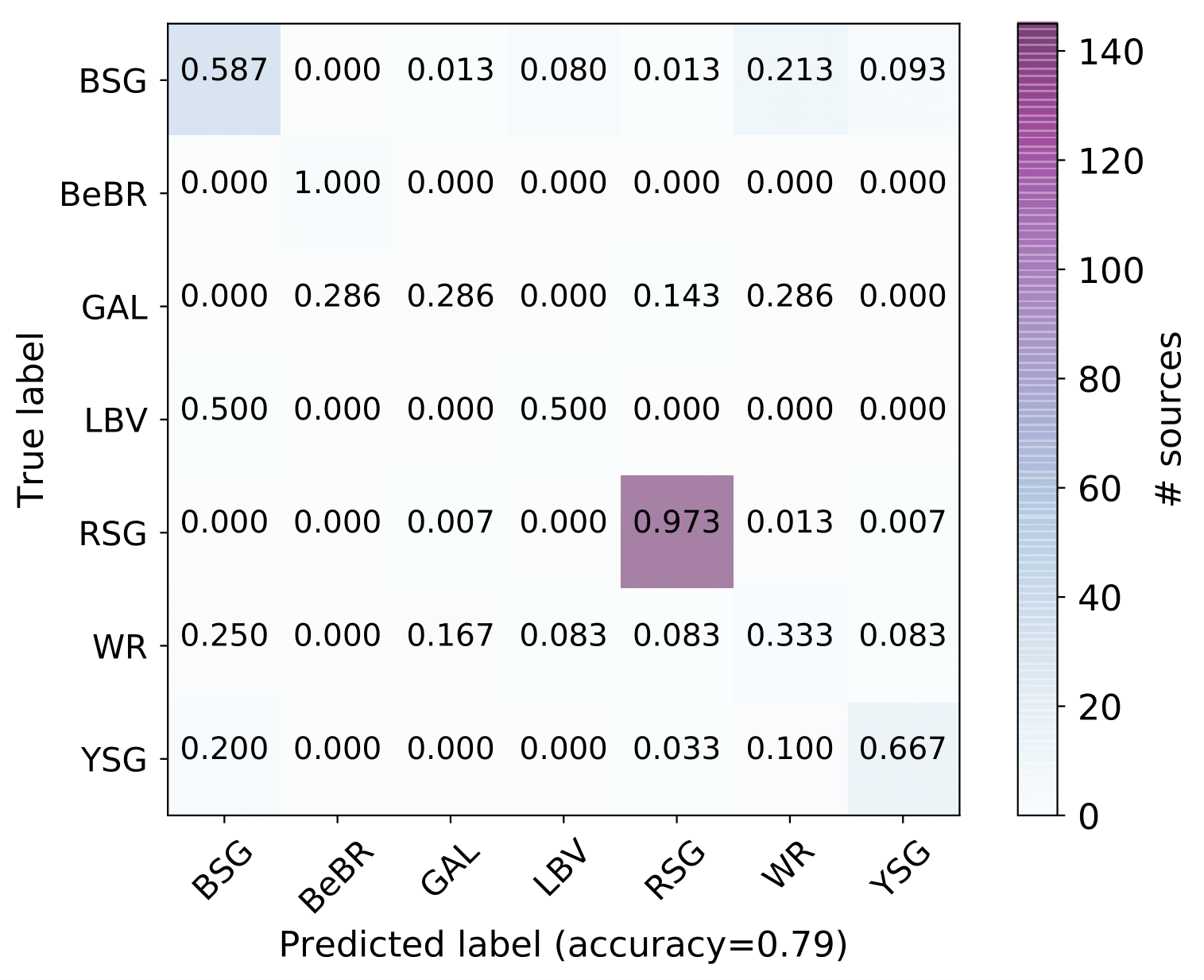
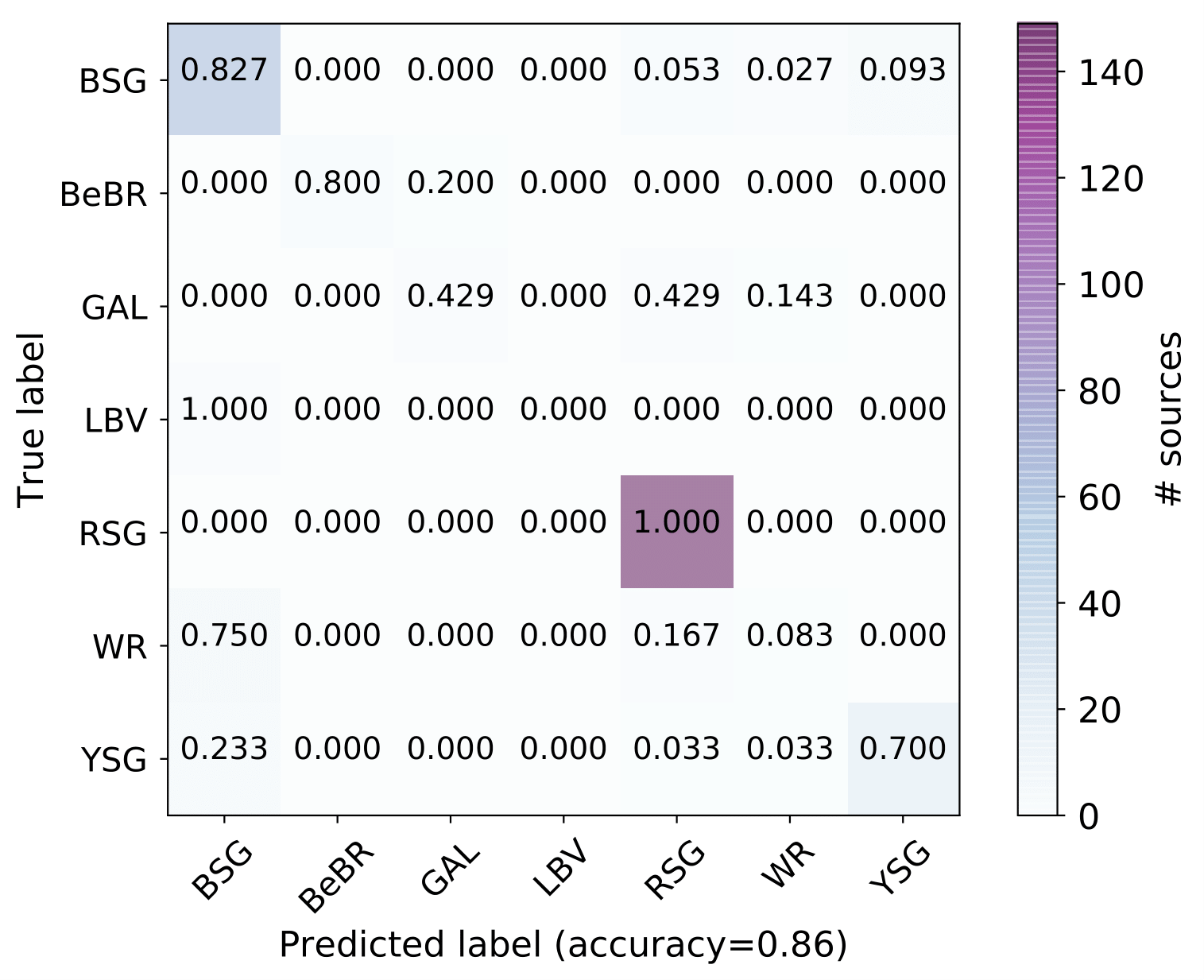
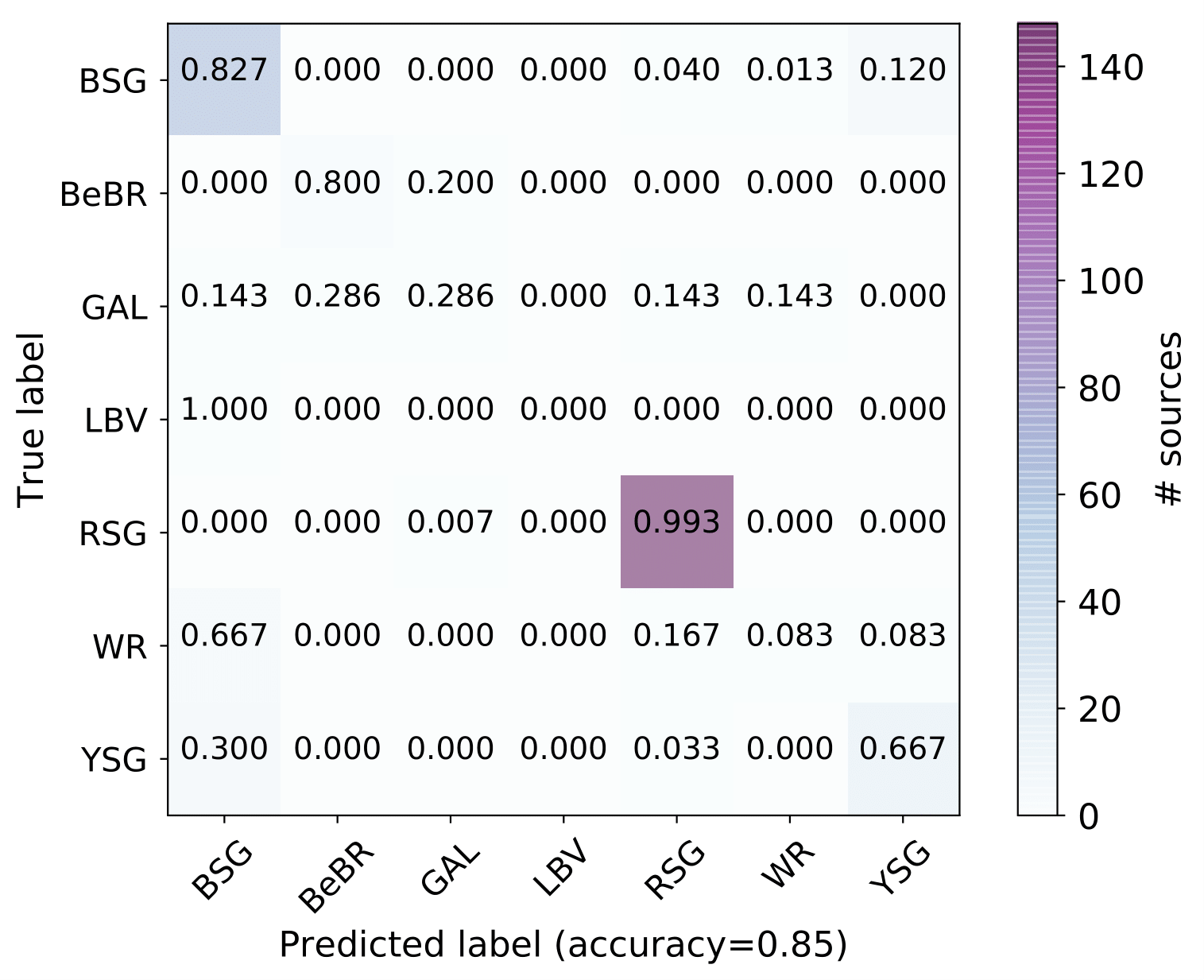
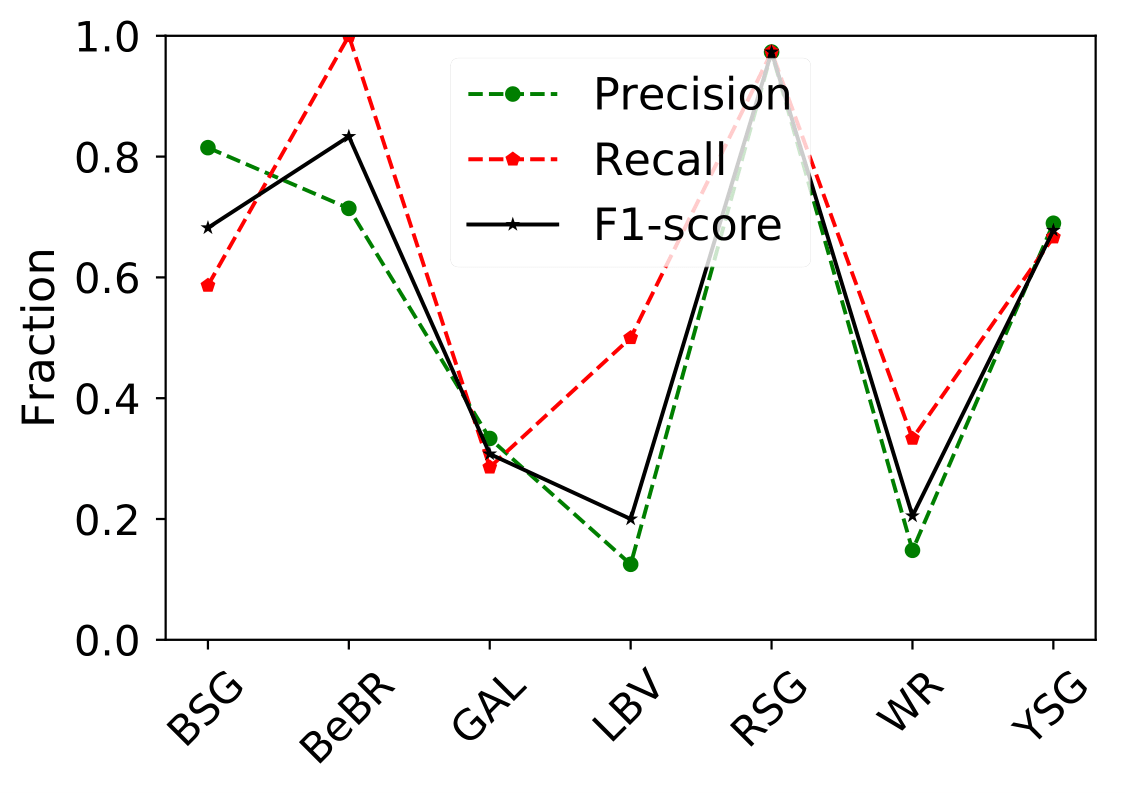
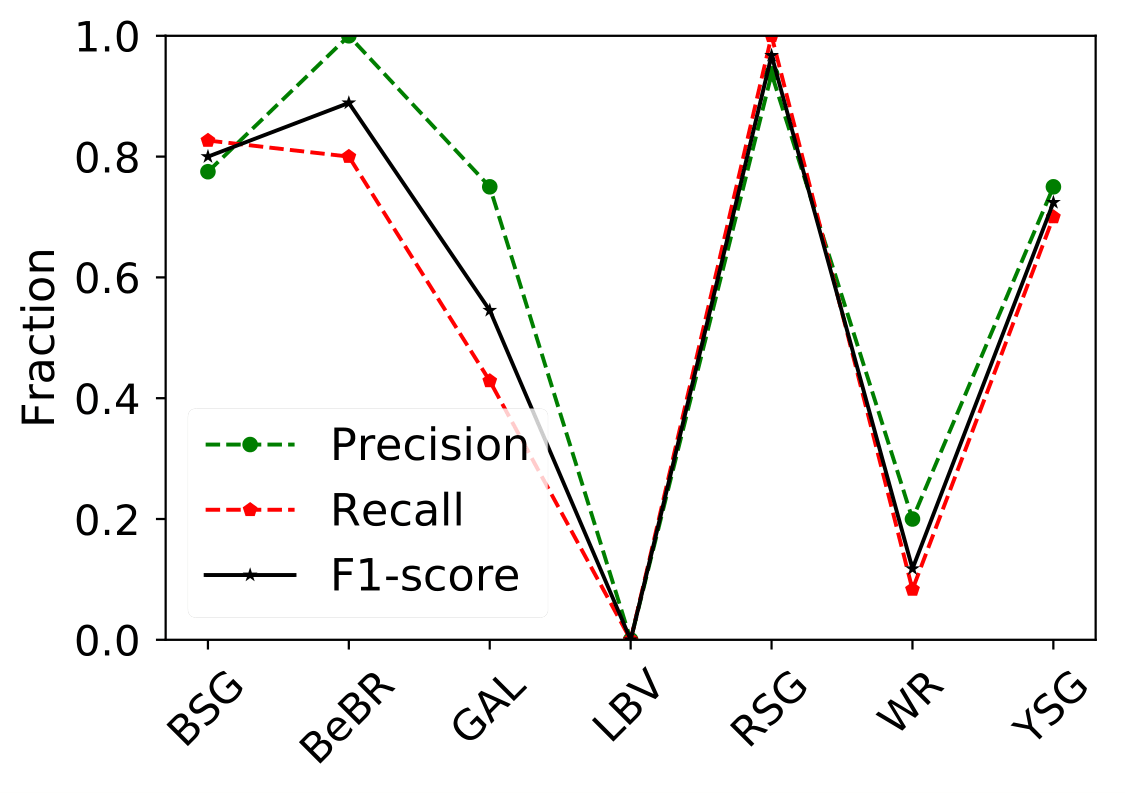
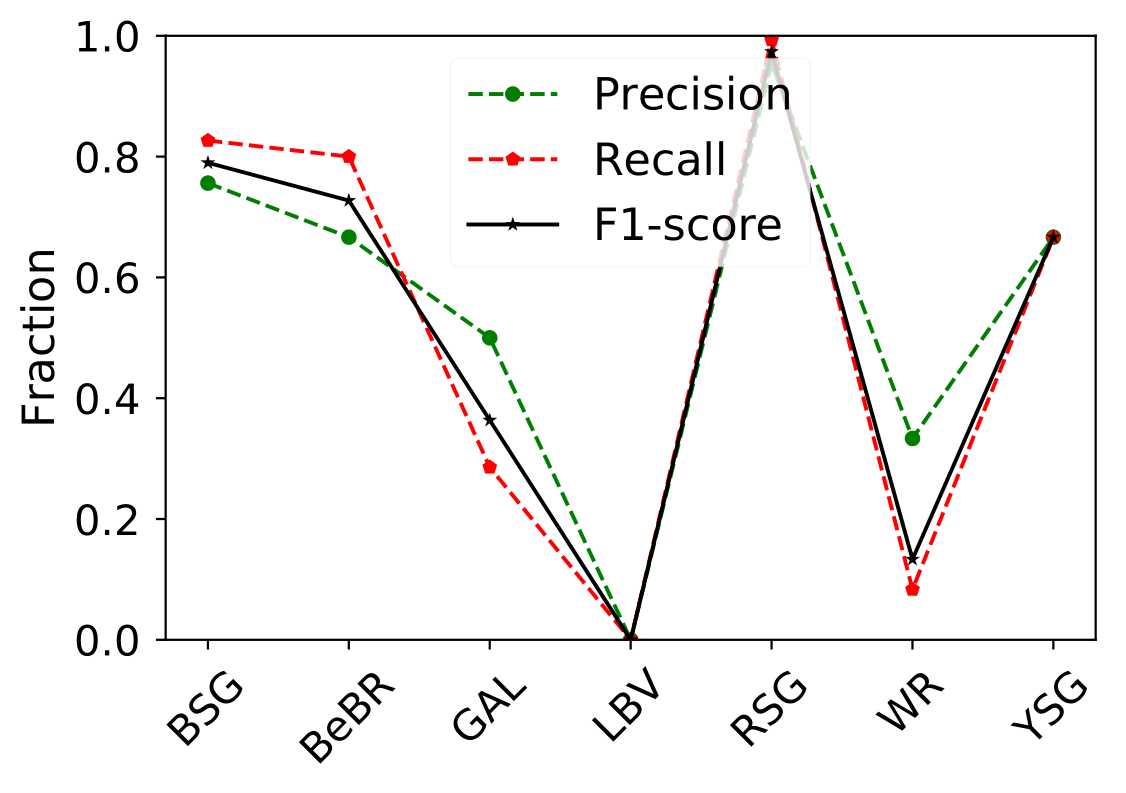
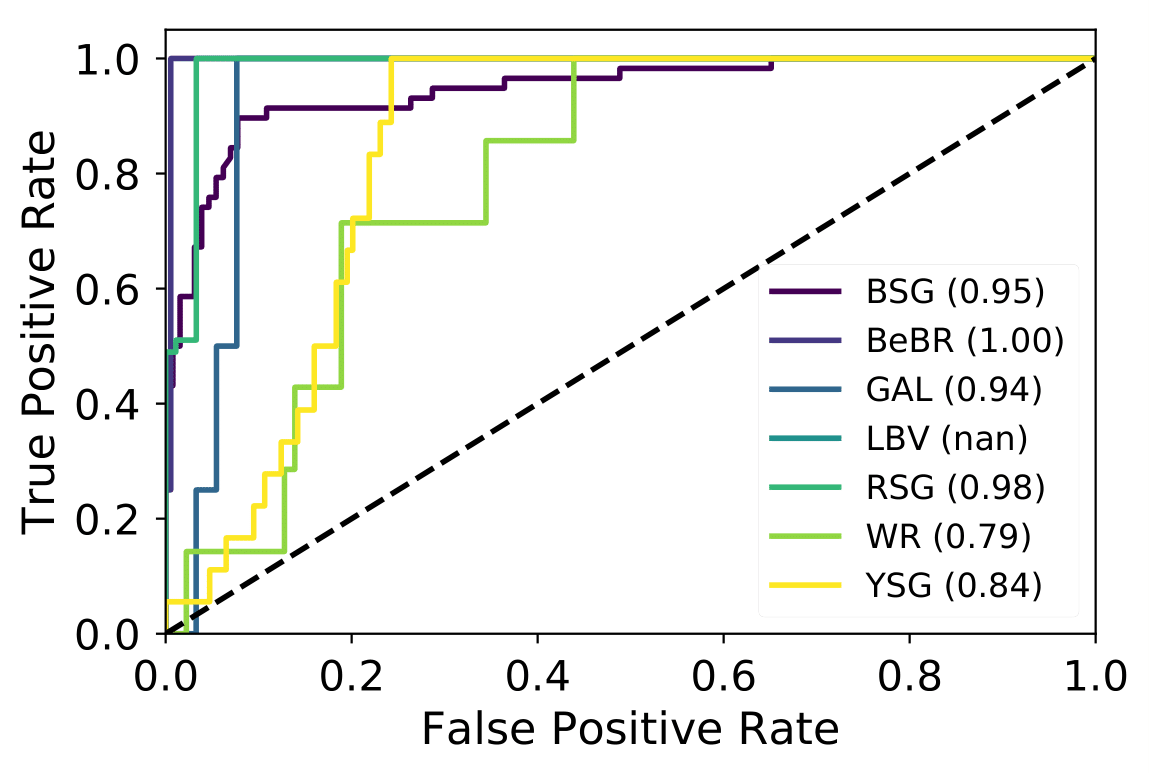
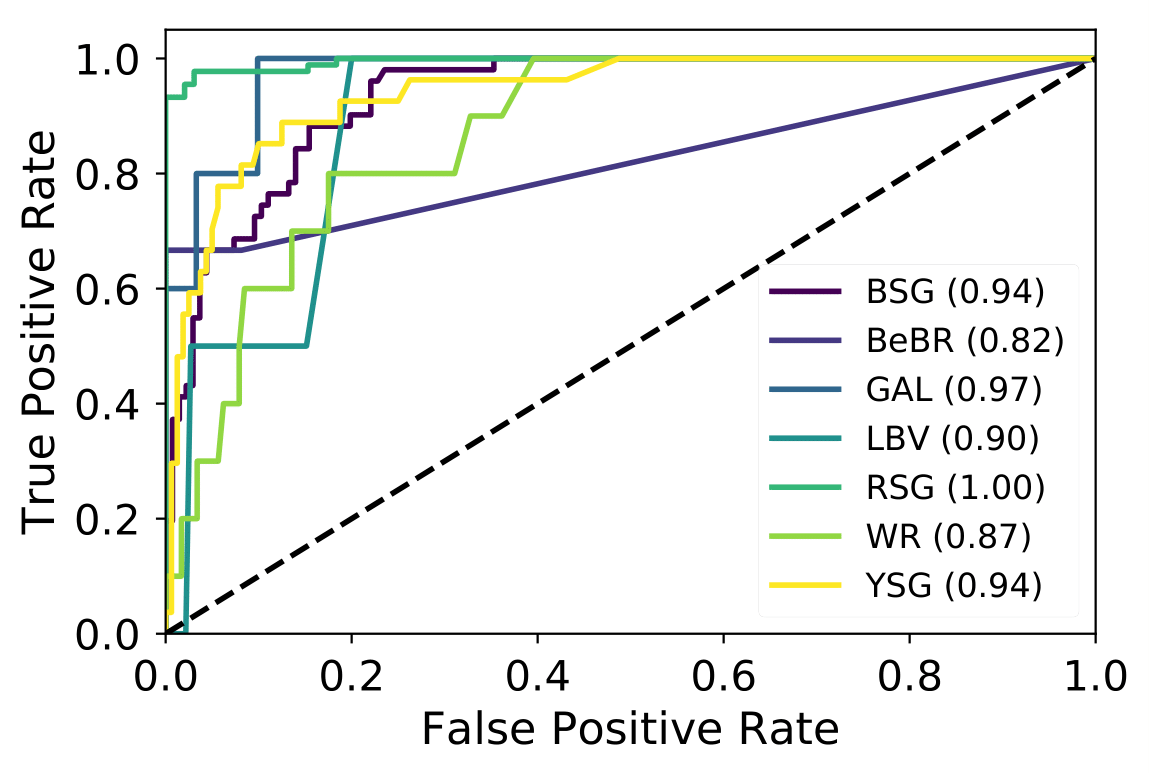
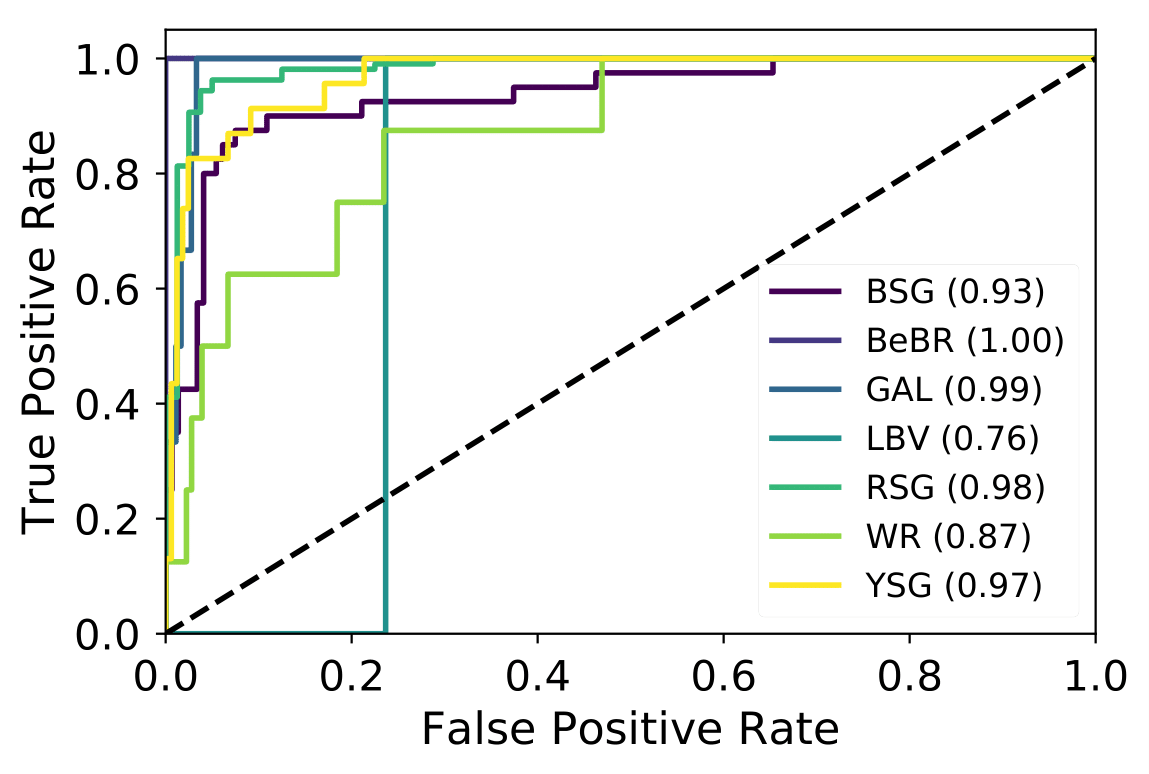
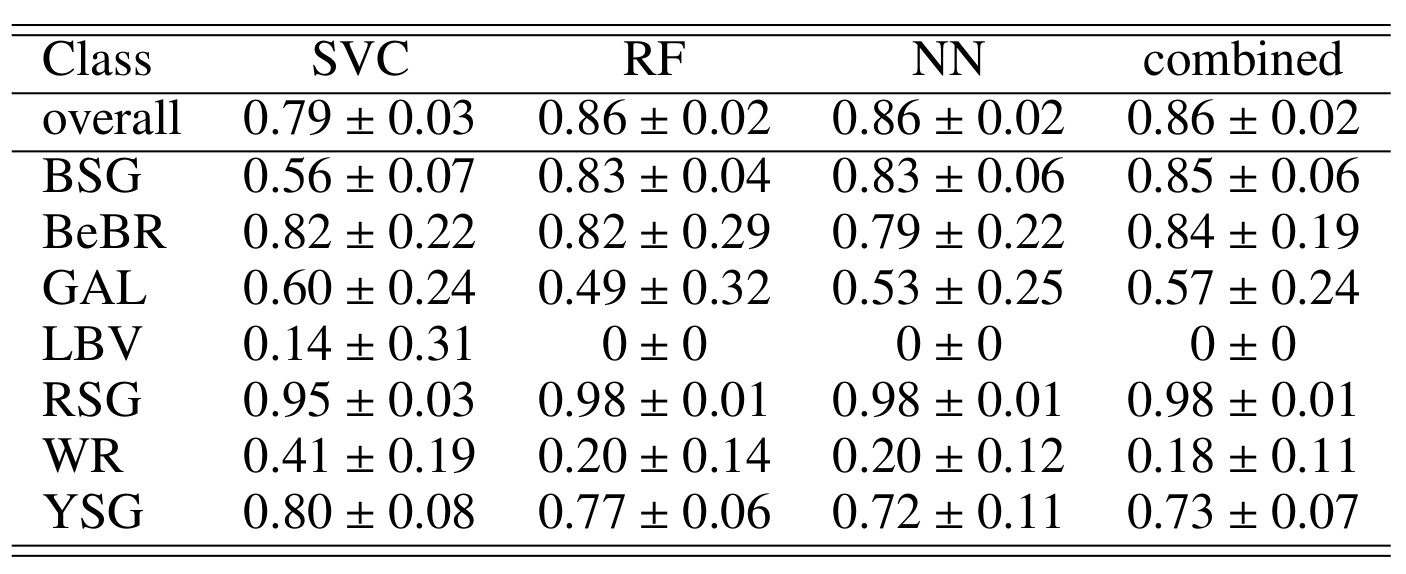
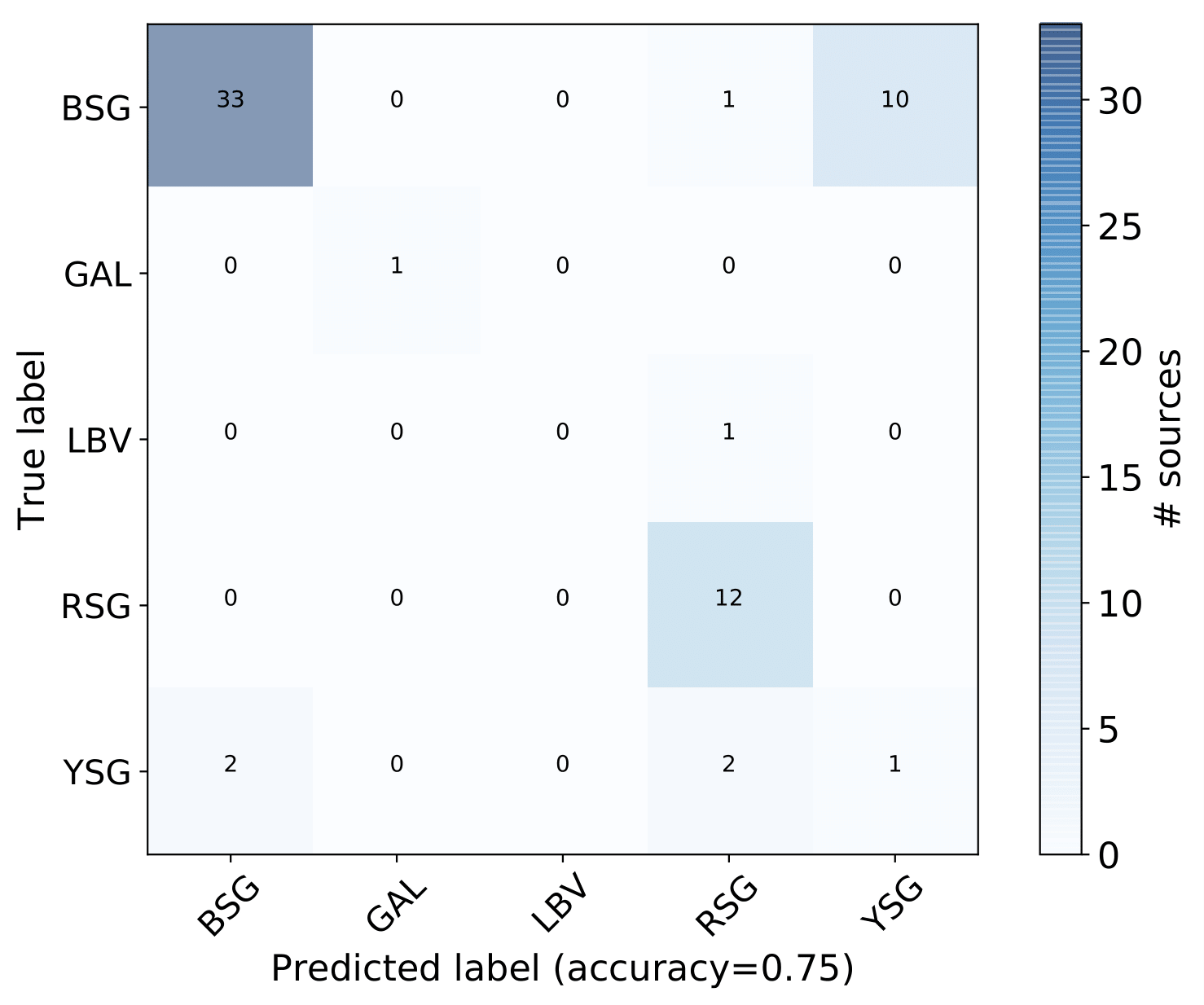
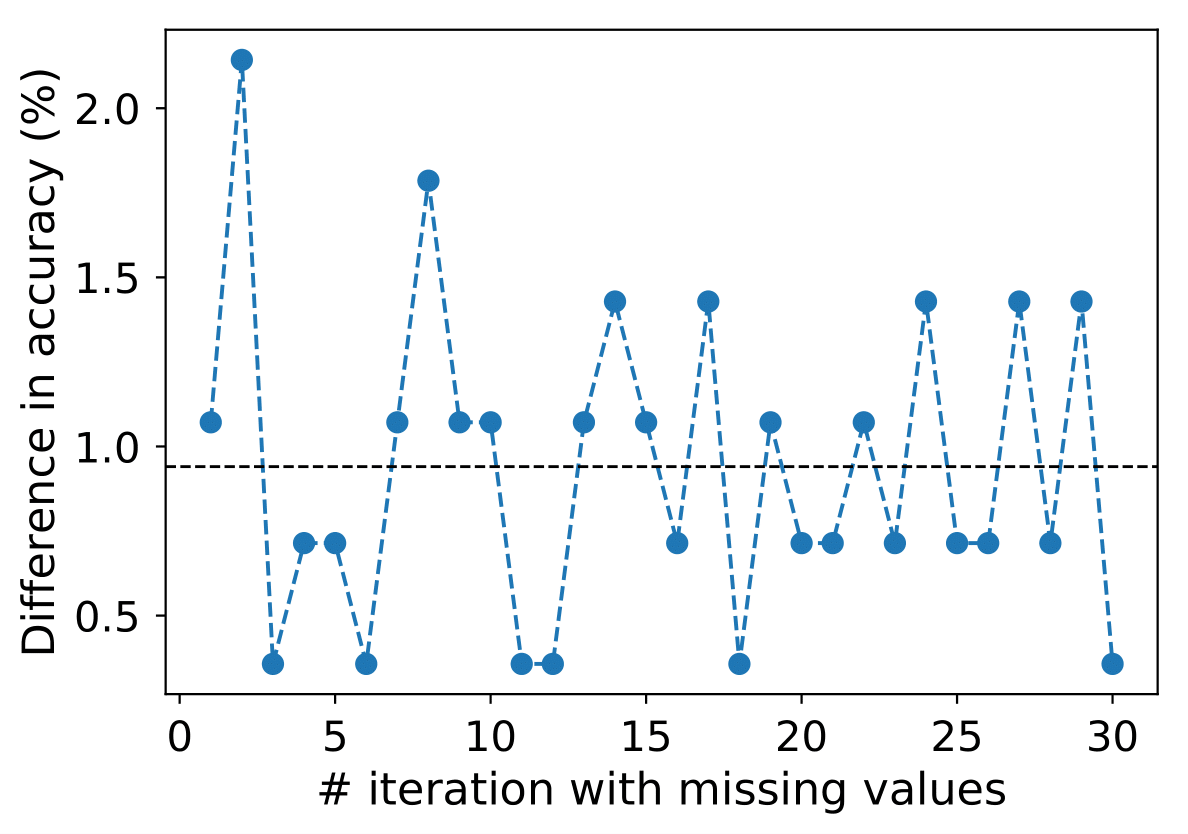
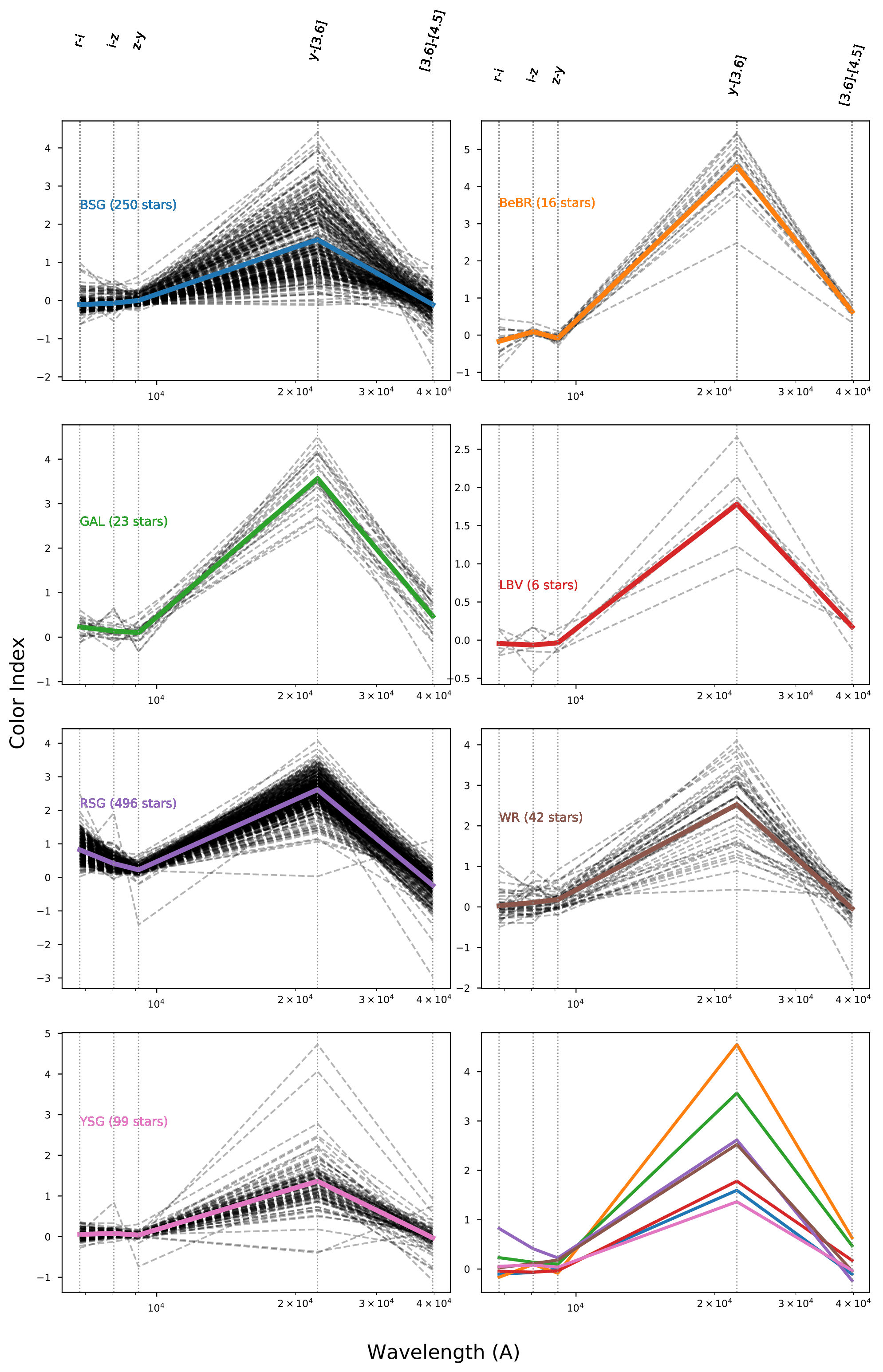
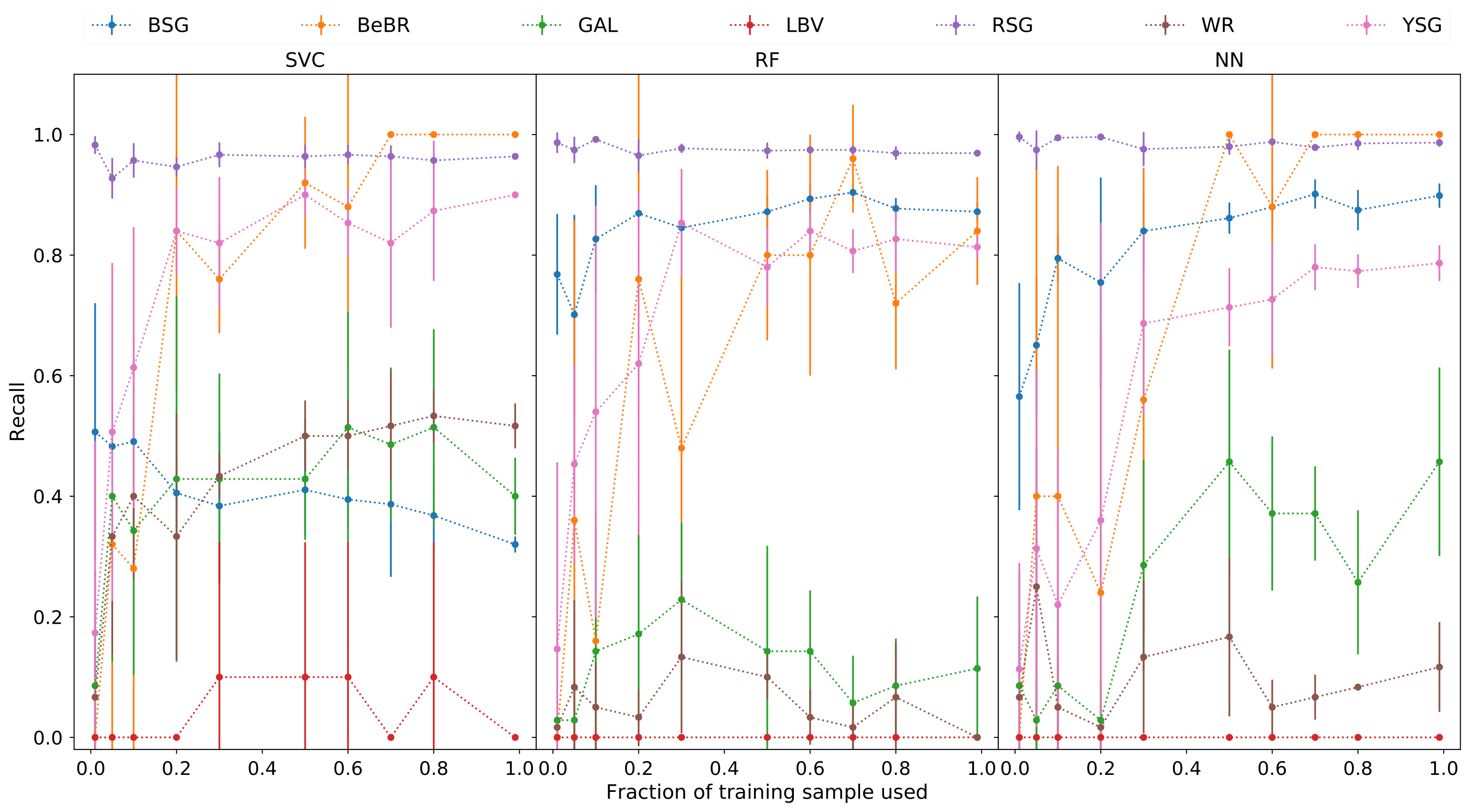
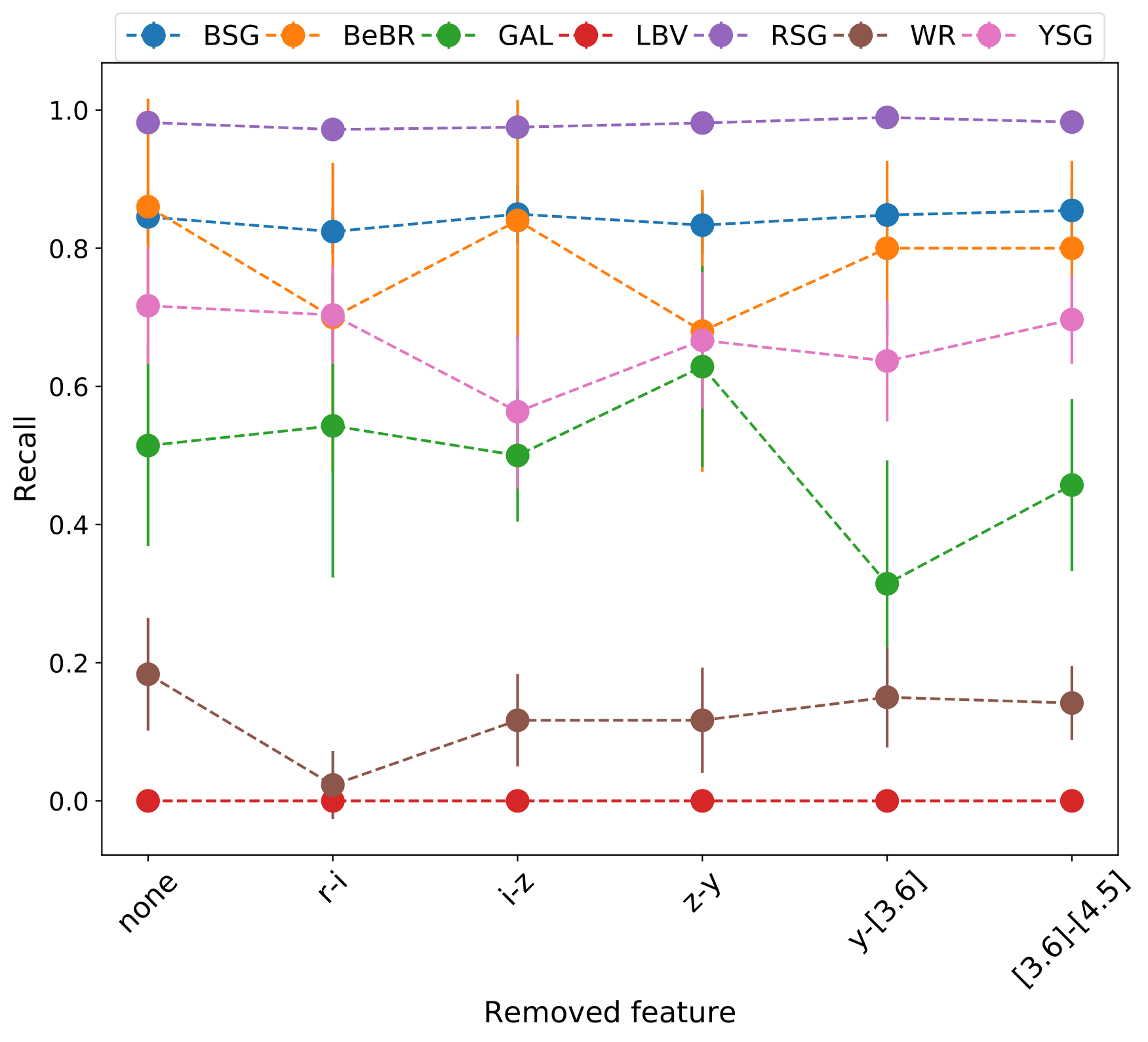
A number of massive stars experience episodic activity and outbursts, e.g. Wolf-Rayet stars (WR), Luminous Blue Variables (LBV), Blue Supergiants (BSG), B[e] Supergiants, Red Supergiants (RSGs), Yellow Supergiants (YSGs).
But ...
How important the episodic mass loss is?
How it depends on the metallicity (in different galaxies)?
What links between the different evolutionary phases exists?