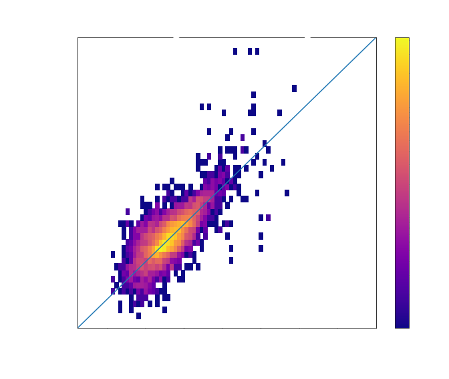
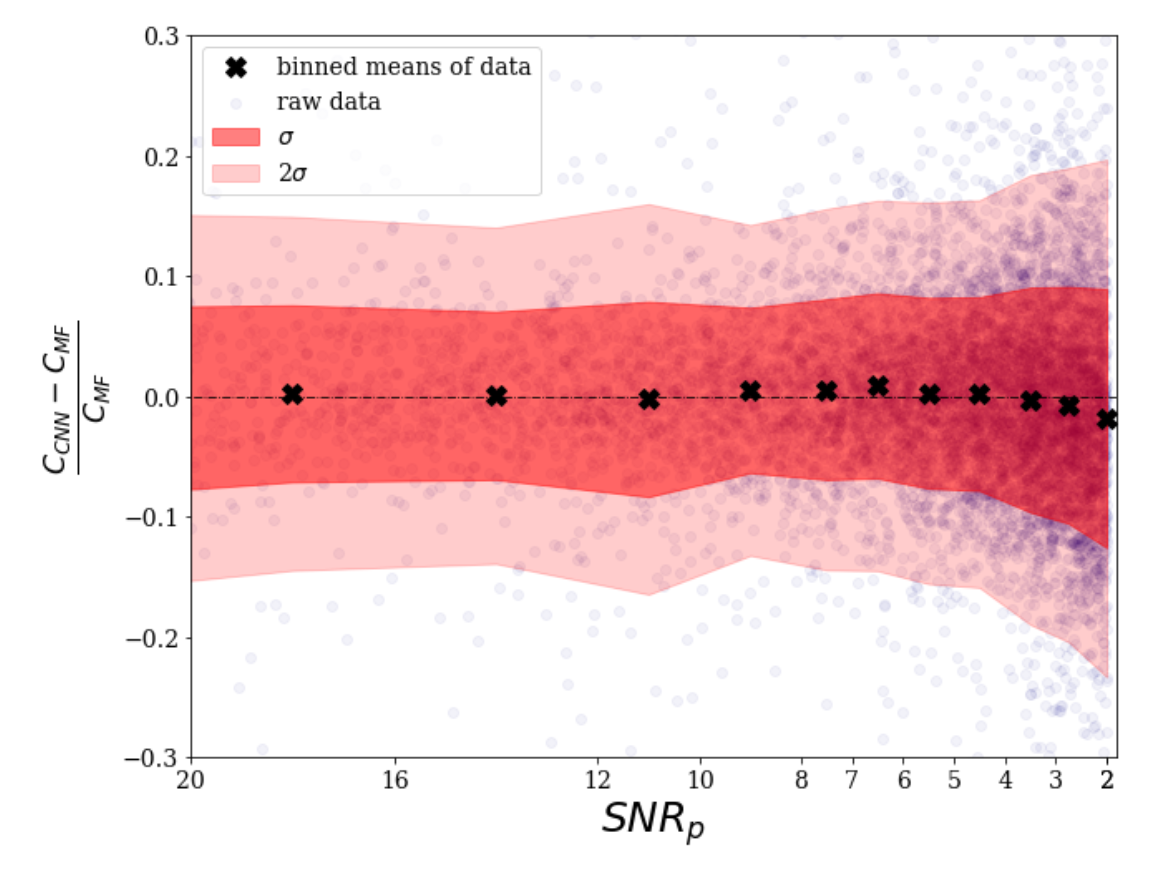
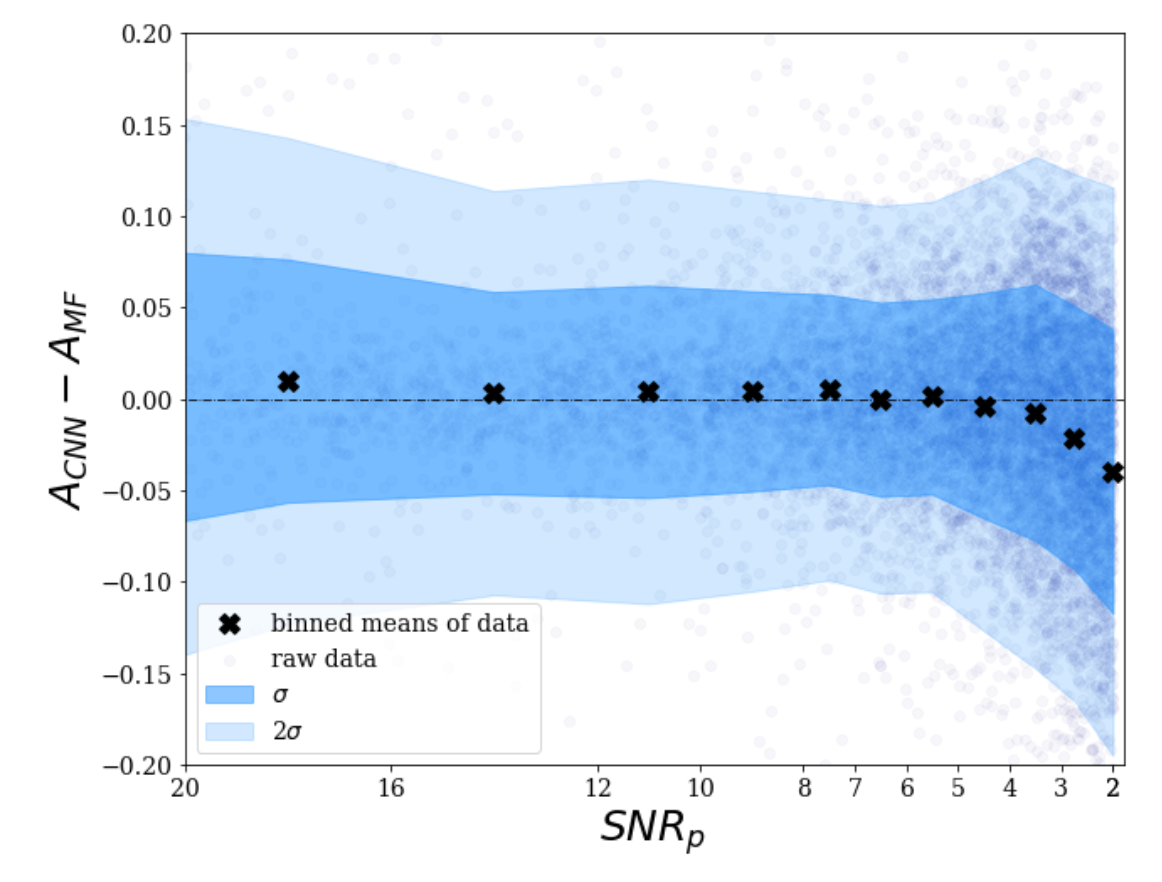
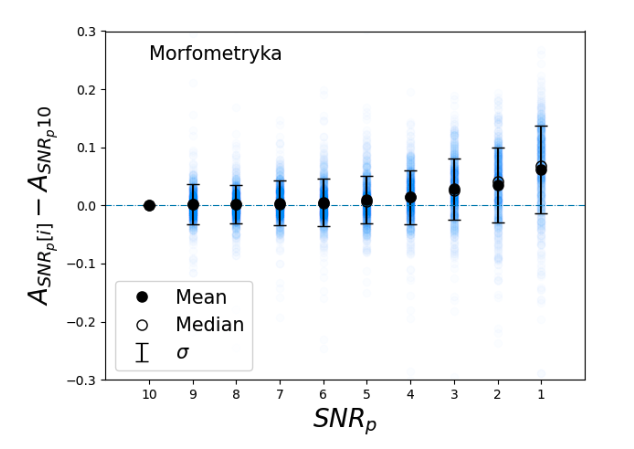
One of the major questions in modern day astronomy is how galaxies evolved from what we see in the distant universe to those that we observe in the local universe. To understand this, we need to understand galaxy morphology.

Figure 1: Hubble classification scheme of galaxy morphology
Galaxy structure has been studied using both parametric and non parametric measurements however, at high redshifts, due to the variety of galaxy types, parametric measurements break down as they assume a smooth light distribution. Non-parametric measurements make no such assumption, thus making them applicable to the high redshift regime.
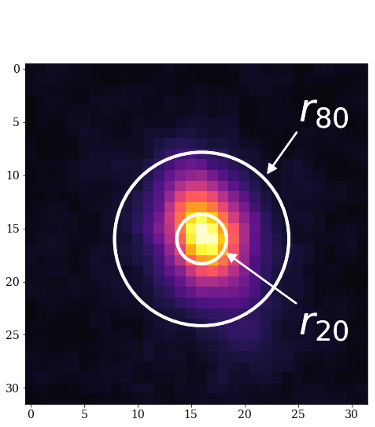
One of the most popular measurement's is the CAS system, which measures the concentration, asymmetry and smoothness of a galaxies light distribution.
These parameters were found to correlate strongly with a galaxies past and ongoing formation modes and are hence useful as a robust classification system.
It has been shown that the concentration parameter correlates with the bulge-to-disk ratio (B/D) of a galaxy, while the asymmetry parameter is a good indicator of the merger history of the galaxy.
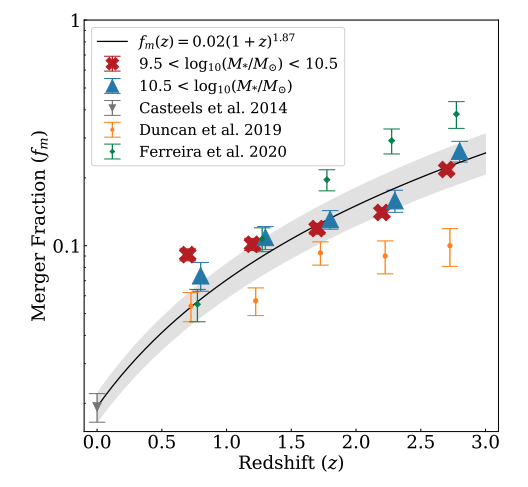
Figure 2: Merger fraction of galaxies in the CANDELS fields calculated using the asymmetry (A) parameter (Whitney et al. 2021).

Figure 3: Relationship between the concentration parameter (C) and the bulge to total light ratio (B/T) of a galaxy (Conselice 2003).
These parameters are simple in definition however, in practice require careful data cleaning and iterative processes. When we scale this up to future large-scale surveys such as Euclid and LSST, the amount of data that we are going to be collecting makes computing these parameters computationally expensive.
What we need to have in place is a more efficient and robust method for computing these parameters.
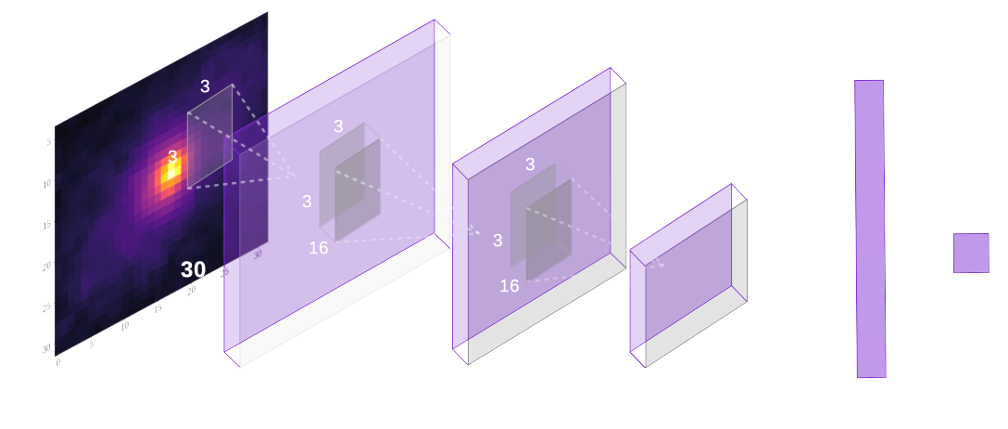
Solution? Machine learning! ML has already been successfully applied to other structural measurements such as the sersic profiles of galaxies (Tuccillo et al 2018).
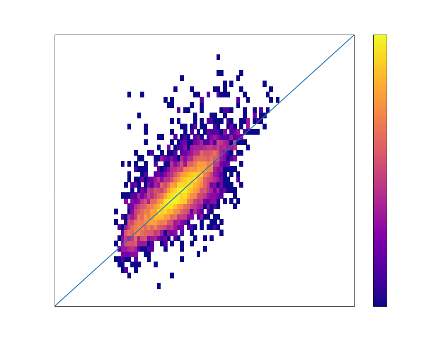
In this work we want to train Convolutional Neural networks to predict both the concentration and asymmetry of a galaxy from a single image.
The work presented in this poster is based on results from Tohill et al. 2021.