Image of the GOTO-1 node on La Palma.
(c) Krzysztof Ulaczyk (2022)
The Gravitational-wave Optical Transient Observer (GOTO) is a fully autonomous wide-field telescope array, designed specifically to hunt the afterglows of gravitational wave events. It is a multi-node, multi-site project, with each node made up of 16x40cm f/2 astrographs, capable of reaching magnitude 19.5 in 60s exposures, with a combined field of view of 47 square degrees. This combination of automation, depth, and wide field makes it uniquely suited for following up a wide range of fast transients, as well as providing a ~nightly cadence all-sky survey for large swathes of the sky.
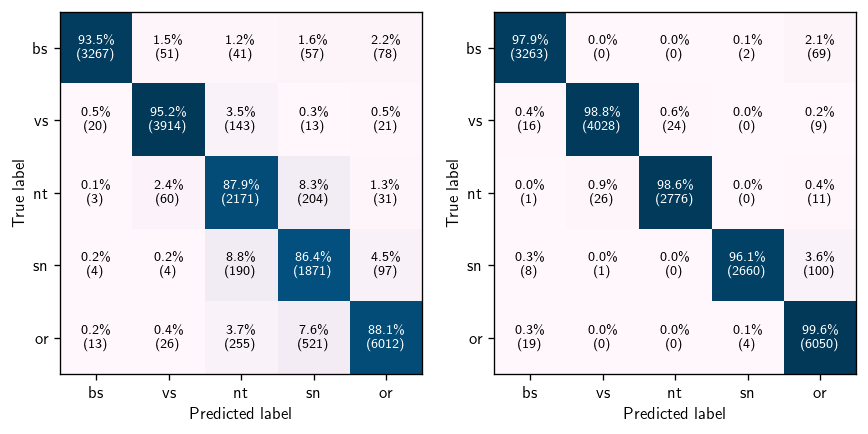
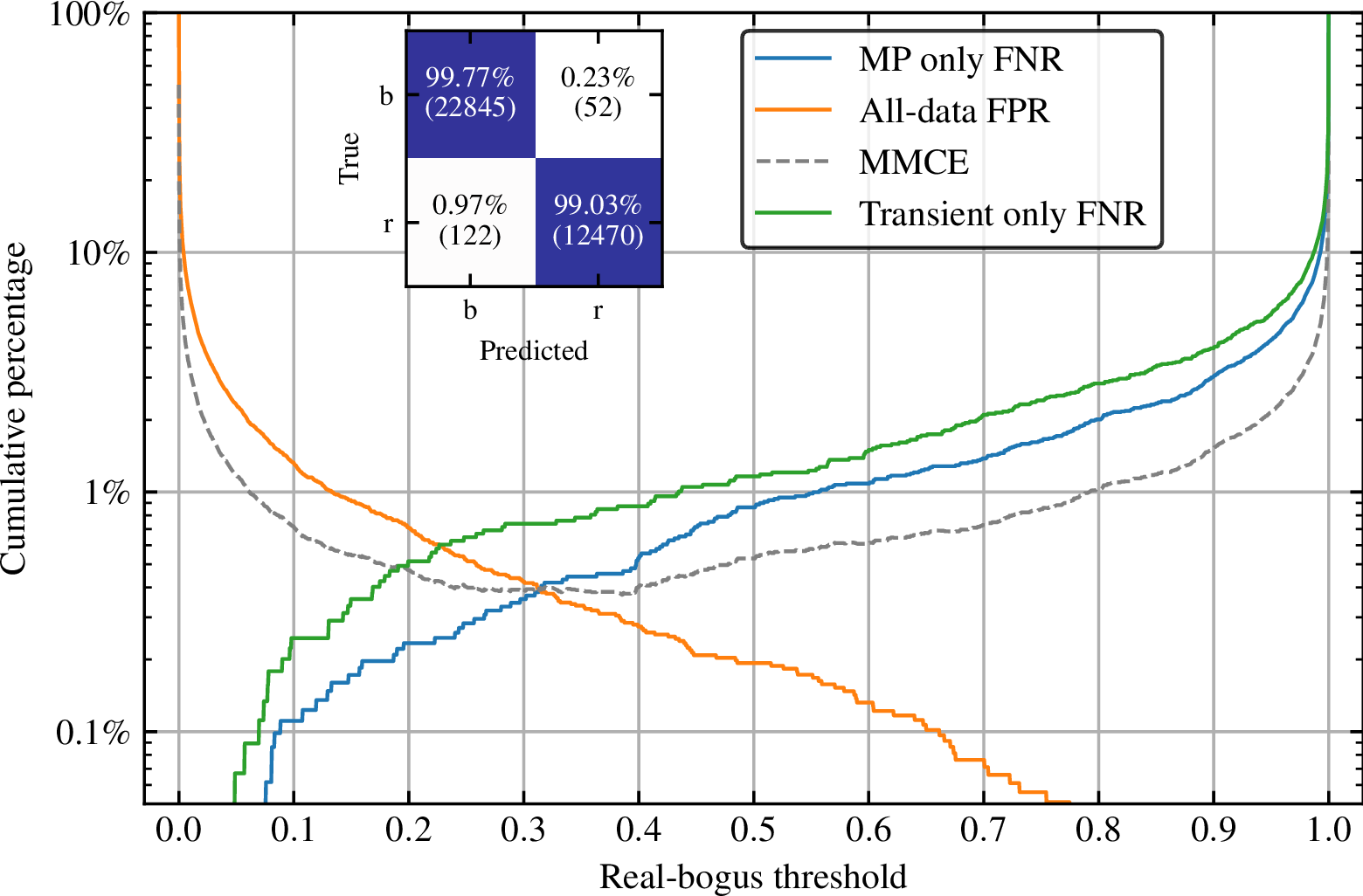
This datastream is significant, with vast scientific discovery potential. GOTO is already accessing regions of transient parameter space that are difficult to probe with other facilities - the GW follow-up strategy is sensitive to a range of fast transients typically inaccessible with the slower cadence of other surveys. However, this is only possible with high-performance pipelines and machine learning filtering - with the burden placed on these scaling with increasing size of facilities. It is clear that the techniques used for last generation's surveys cannot be used in the upcoming LSST era, let alone with current sky surveys like GOTO and ZTF. It is therefore crucial to keep improving our classifiers, with even marginal percentage gains in accuracy adding up to 10s of thousands less candidates for humans to vet over a typical week. These algorithms have slowly climbed in accuracy over the past years with the introduction of deep learning.